MaxDiff Analysis Using CBC/HB v5.x
In this section, we assume you own the CBC/HB v5.x software and have prepared a .CHO file containing respondent data. You obtained the .CHO file by clicking File | Data Management | Export Data and by adding an export that has an Export Settings Type of MaxDiff.
When you prepare the .CHO file, a number of other files are created that (although not required) are useful for setting up your CBC/HB project:
ExerciseName.ATT (Attribute file)
ExerciseName.EFF (Effects file)
ExerciseName.VAL (Values file)
ExerciseName.MTRX (Default Prior Covariance Matrix)
Open the CBC/HB v5.x software. Browse to and open the .CHO file. CBC/HB v5 will recognize the presence of the .ATT, EFF, .VAL, and .MTRX files when placed in the same folder as the .CHO file. It will prompt you to import these files as well.
Once you have imported the data (along with the optional files), note that there will be k-1 total attributes in the study (to avoid linear dependency, meaning that one of the columns can be perfectly predicted by a linear combination of other columns), representing your k total items in the MaxDiff design. The final item will be constrained to have a utility of zero, and the remaining items are estimated with respect to the final item's score.
We should note that when using HB to estimate parameters for many items under dummy coding, the estimates of the parameters (relative to the reference "0" level) can sometimes be distorted downward, often quite severely when there are many items in the study and when the number of questions asked of any one respondent is relatively few. (This distortion of course makes it appear as if the "omitted" item's estimate is "too high" relative to the others.) To avoid this difficulty, we automatically export the ExerciseName.MTRX file containing an appropriate prior covariance matrix. The proper prior covariance matrix for use with MaxDiff exercises is a (k-1) x (k-1) matrix of values, where k is equal to the total items in your MaxDiff study. Make sure the custom prior covariances file (the information from .mtrx) is actually being used by checking that the Use a Custom Prior Covariance Matrix box is check on the Advanced tab.
If you examine the .MTRX file (with a text editor), you will find a matrix composed of "2"s across the main diagonal, and "1"s in the off-diagonal positions (assuming you are using the default prior variance specification of 1.0), such as:
2 1 1 1 . . .
1 2 1 1 . . .
1 1 2 1 . . .
1 1 1 2 . . .
. . . . . . .
. . . . . . .
. . . . . . .
If you had requested a different prior variance, the values in this matrix are multiplied by the desired variance constant.
When you have finished these steps, click Estimate Parameters Now... from the Home tab. Weights for the scores are written to the .HBU and .CSV files. Remember, the weight of the reference value (the last item in your design that was omitted) for each respondent is 0 (you'll need to fill this in when done). The other items are estimated with respect to that reference item.
We strongly encourage you to consider using covariates in your HB run, employing questions asked elsewhere in the questionnaire that are predictive of differences in item scores between respondent segments.
Transforming Weights to 0-100 Scale
To convert the raw weights to the 0-100 point scale, first zero-center the weights by subtracting the mean weight for each respondent from each respondent's weights. Then, perform the following transformation for each zero-centered item score for each respondent:
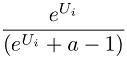
Where:
Ui = zero-centered raw logit weight for item i
eUi is equivalent to taking the antilog of Ui. In Excel, use the formula =EXP(Ui)
a = Number of items shown per set
Finally, as a convenience, we rescale the transformed item scores by a constant multiplier so that they sum to 100.
The logic behind this transformation is as follows: We are interested in transforming raw scores (developed under the logit rule) to probabilities true to the original data generation process (the counts). If respondents saw 4 items at a time in each MaxDiff set, then the raw logit weights are developed consistent with the logit rule and the data generation process. Stated another way, the scaling of the weights will be consistent within the context (and assumed error level) of choices from quads. Therefore, if an item has a raw weight of 2.0, then we expect that the likelihood of it being picked within the context of a representative choice set involving 4 items is (according to the logit rule):
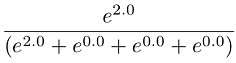
Since we are using zero-centered raw utilities, the expected utility for the competing three items within the set would each be 0. Since e0 = 1, the appropriate constant to add to the denominator of the rescaling equation above is the number of alternatives minus 1.